
.svg)
How does ChatGPT work: Intro to LLMs

April 25, 2024
- Skeleton
- Traditional ML
- Trained on labelled data, loss function tells you how wrong your model is, and then we use gradient descent to roll to the bottom of the curve and minimize the error. We could now detect objects (like how your phone detects your face on Snapchat), classify images (Google Image Search was born from this),
- Each model was trained for a very specific task. It also needed labelled data, which is a labour intensive process. Imagine having to go through and label 1000 pictures of
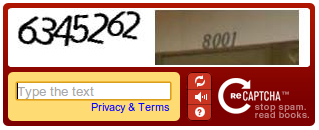
- Sidenote: reCAPTCHA is rumoured to be collecting data for Google from millions of people to train models for their OCR algorithms, Google Maps, and self driving cars at Waymo.
- Traditional ML
- Transformer architecture
- Predict the next token
- “tomorrow, biden will be… “ requires a lot of knowledge about the world to be able to predict the next word
- Language models are few shot learner’s paper for example.
- Used sentences on the internet and showed snippets of sentences, paragraphs, and documents, and asked models to predict the next word.
- Being able to predict the next word teaches you about what words mean in context to each other, and build up an understanding of reasonable language in that way.
- Simple framework to collect a TON of training data.
- We also got a LOT of data. trillions of words from the internet.
- No labelling necessary since we can already see what the next word is supposed to be if we show truncated sentences
- [show image]
- We call these transformer models Large Language Models, or LLMs for short.
- Reasonable language contains so much information about us, the economy, and the world.
- People wonder if we’ve encoded a representation of the entire human race into these language models by training it on the internet.
- This scale of data going into huge models with tens and hundreds of billions of parameters unlocked Gen AI’s potential.
- Models have general understanding and can perform well on a lot of tasks without specifically being trained on these tasks
- E.g. can write emails, summarize texts, have conversations, extract information, all from the same model.
- Can just prompt the same model to use it for the use case you want, just like you can ask the same person to do different tasks by giving them clear instructions.
- Don’t have to grow new humans for specialized tasks.
- Predict the next token
- Examples of LLMs
- Benchmarks explained
- Leaderboard snippet
- Transformer architecture
In this article, I want to clearly outline the difference between “traditional” machine learning (ML), and Generative AI. This is targeted towards a non-technical audience. If you’ve ever wondered:
- What made ChatGPT work
- Why it feels so different from other forms of “AI” we’ve interacted with before
I want to give simple, intuitive answers to these questions here.
Reading time: 6 minutes
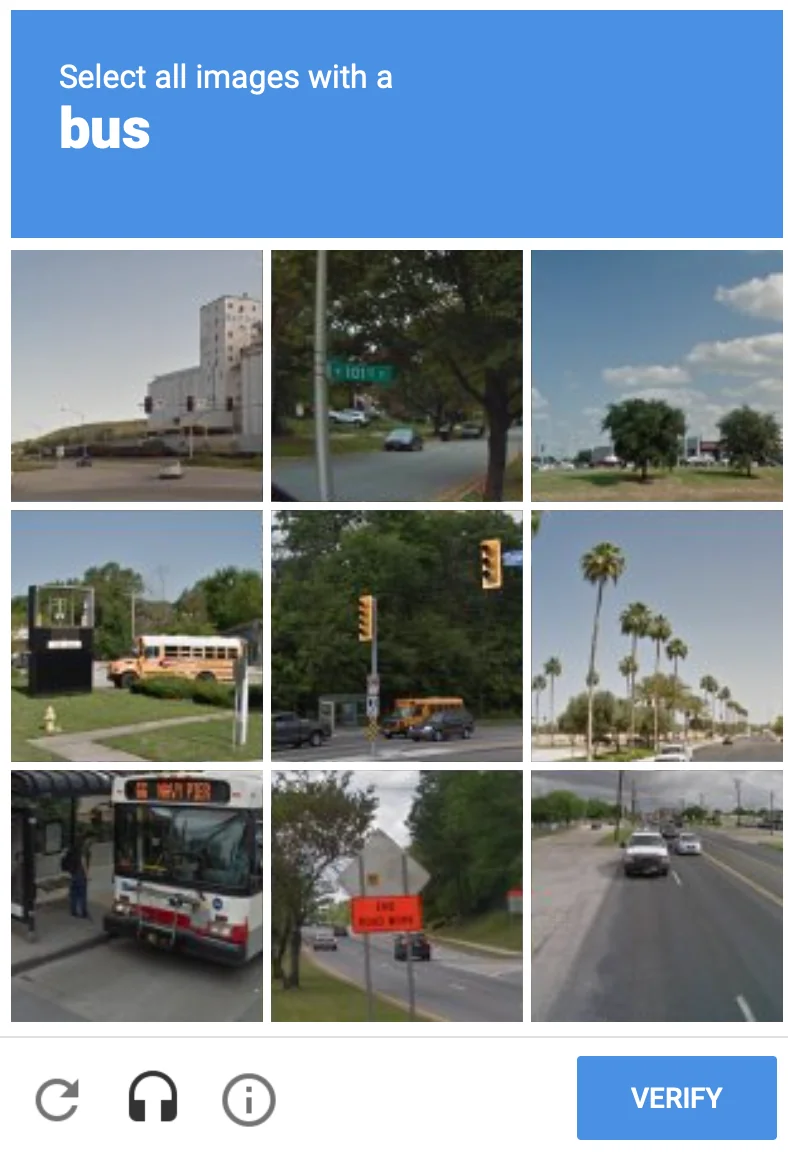
Machine learning is broadly split into supervised learning, unsupervised learning and reinforcement learning. Traditional ML approaches within supervised and unsupervised learning were promising, but previously faced certain bottlenecks.Supervised learningSupervised learning is a method where a computer learns to perform a task by studying many labeled examples provided by a teacher, allowing it to then accurately handle new, unseen instances of the task on its own. For example, if you are training a model to identify the difference between trucks and cars, you show it thousands of images of trucks and cars, and tell the model for each image whether it is a truck or a car.It learns to recognize the differences between the two, and can now make guesses about images it hasn’t seen before to identify trucks and cars.
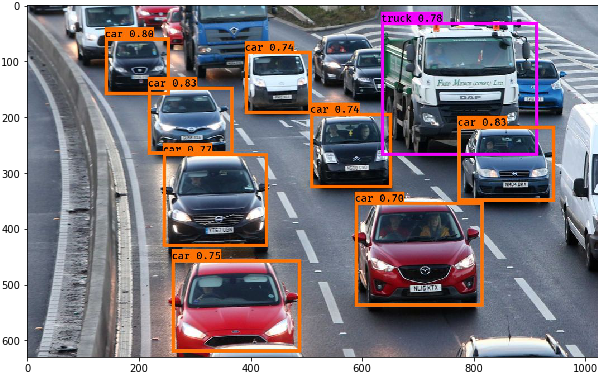
This approach has led to significant advancements in object detection (like facial recognition on Snapchat) and image classification (the foundation of Google Image Search).However, there are two major bottlenecks with supervised learning:
- Each model can only perform the specific type of task you train it for.
- To go back to the car and truck example, if you show the model a picture of a motorbike, it won’t know what to do with it.
- Each model requires humans to label thousands, if not millions of data points. This is painful, time consuming, and very expensive.
- Side-note: reCAPTCHA is rumored to be collecting data from millions of people to train models for Google's OCR algorithms, Google Maps, and Waymo's self-driving cars
Unsupervised learningUnsupervised learning is a method where a computer learns to find hidden patterns or structures in a dataset on its own, without being given any labeled examples or specific guidance on what to look for.It can be used to automatically group similar news articles together based on their content, without needing humans to pre-categorize any articles, allowing readers to easily discover related stories and topics.
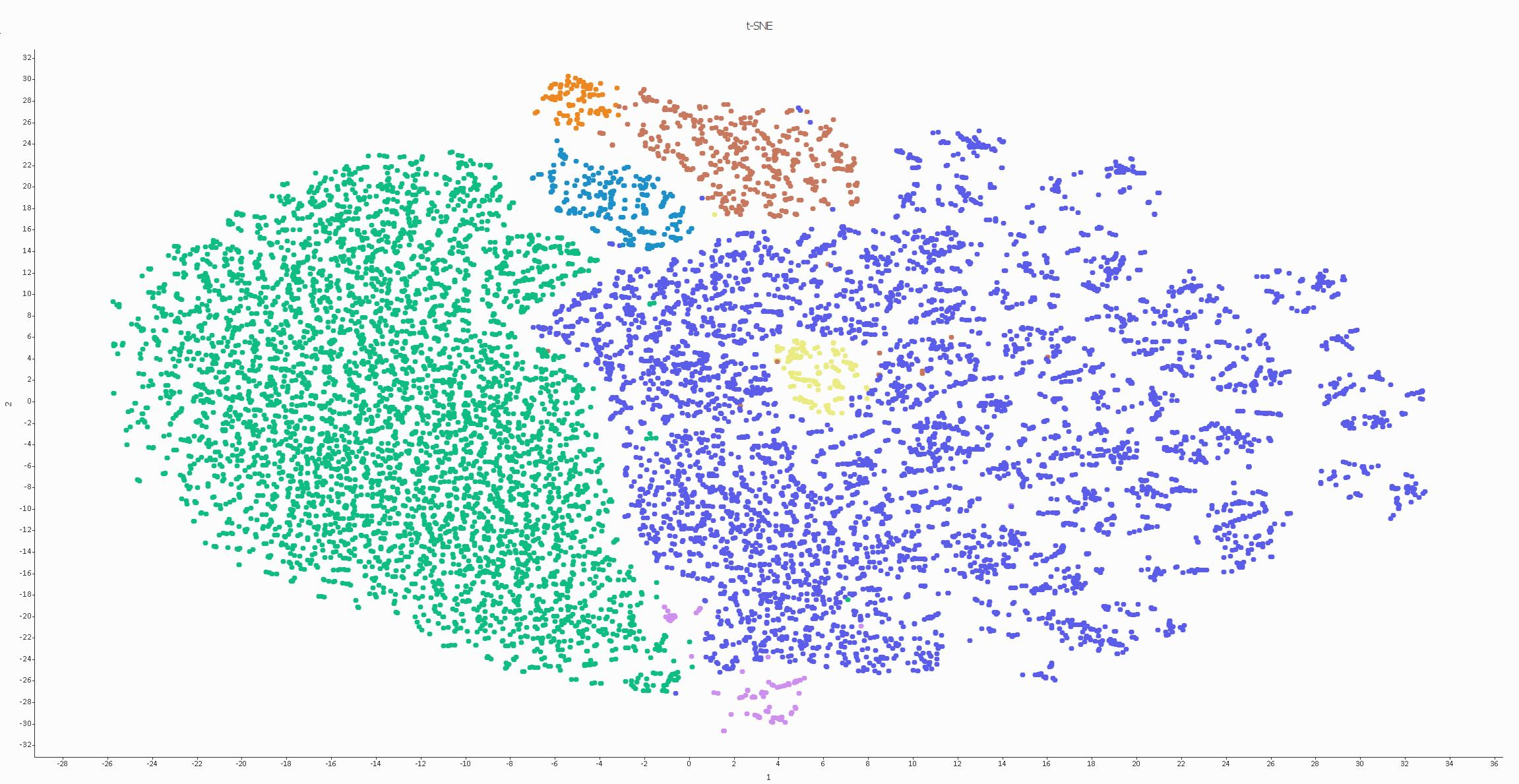
We can then go and look at examples of datapoints in each cluster to identify what categories has the model divided the data into. If done correctly, we could identify topics in the clusters above and categorize them into something like below. All without labelling anything! The AI just finds and marks out patterns, and we need to make sense of those patterns to see if there are any interesting insights that come out of that.
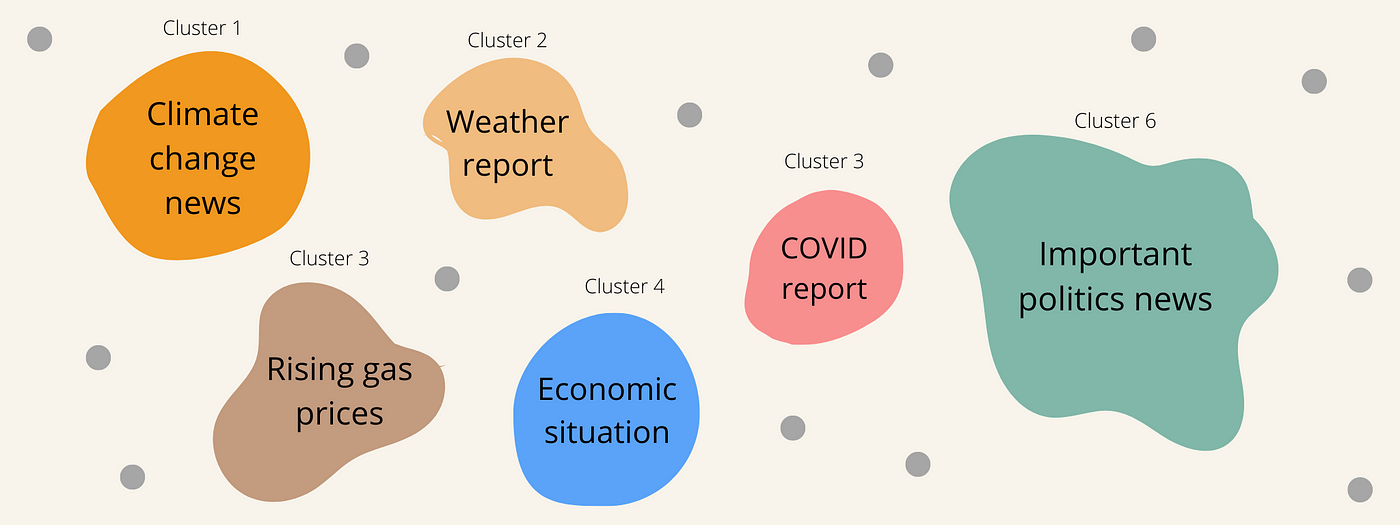
Two of the biggest problems with traditional unsupervised learning approaches were:
- Difficulty in interpretation: When a computer learns from data without being told what to look for, there's no preset correct answer or outcome to compare the output against (we call this “ground truth” in ML). We could get the model finding a bunch of patterns that look completely random to us.
- Lack of clear objectives. Unlike supervised learning, where the computer is given a clear task to learn, it’s hard to align the patterns that unsupervised learning can identify with actual useful insights that we can use to make decisions or take actions.
Language modelsDeveloping a model like ChatGPT involves three main phases: pretraining, supervised finetuning, and RLHF.Pre-training for completionThe first phase is pre-training, where a large language model (LLM) is trained on a massive amount of text data scraped from the internet to learn statistical information about language, i.e. how likely something (e.g. a word, a character) is to appear in a given context.If you're fluent in a language, you have this statistical knowledge too. For example, if you’re fluent in English, you instinctively know that "green" fits better than "car" in the sentence "My favorite color is __."A good language model should also be able to fill in that blank. You can think of a language model as a “completion machine”: given a text (prompt), it can generate a response to complete that text.As simple as it sounds, completion turned out to be incredibly powerful, as many tasks can be framed as completion tasks: translation, summarization, writing code, doing math, etc. For example, give the prompt: How are you in French is ..., a language model might be able to complete it with: Comment ça va, effectively translating from one language to another.This completion approach also gave us the ability to train models on HUGE amounts of data from across the internet without needing human labelers.Here’s the approach:
- Take a snippet from the internet. We’ll use the sandwich article from Wikipedia as an example. We’ll hide the end of the sentence and pass the first bit into the model.

- The model may say something like “Sandwiches are a popular type of lunch food, taken to work and school by people who want something portable to eat.”
- We then reveal what the sentence actually was, and train the language model to reduce the difference between its generated output and the actual Wikipedia sentence we were expecting.

Since we don’t need to create data for each example, and can instead leverage the trillions of words that we have on the internet for our data instead, this was a massive step up in the amounts of data we could train the model on.Supervised FinetuningWe’ve taught the model about completing language through pretraining. However, when you ask the pretrained model a question like "What are the best tourist attractions in Paris" any of the following could be correct completions:
- Adding more context to the question:
for a family of four? - Adding follow up questions:
? Where should I stay? - Actually giving the answer:
The Eiffel tower, the Champs-Élysées, and Arc de Triomphe are all popular destinations.
When using a model like ChatGPT, we are probably looking for an answer like option 3. Supervised finetuning allows us to show the model these examples of questions and ideal answers (known as demonstration data), so the model mimics the behavior that we want it to. OpenAI calls this approach “behaviour cloning”.Demonstration data for behaviour cloning is generated by highly educated labelers who pass a screen test. Among those who labeled demonstration data for InstructGPT, ~90% have at least a college degree and more than one-third have a master’s degree.These people are called “AI tutors” in industry, and need to be subject specific: they are the ceiling on what your model can be. If you want to make your model better at code generation, you need great software engineers. Improving summarization capabilities? You could benefit from hiring specialized newspaper editors.Reinforcement Learning through Human Feedback (RLHF)The third phase is RLHF, which consists of two parts.First, a reward model is trained to act as a judge that measures the quality of a response given a prompt. This is done by having human labelers compare different responses and decide which one is better. Once trained, the reward model simulates human preferences, so if it likes a response, it’s likely that a human user would too, therefore that response will be rewarded.Once trained, the reward model is used to further improve the fine tuned model using reinforcement learning techniques, such as Proximal Policy Optimization (PPO).
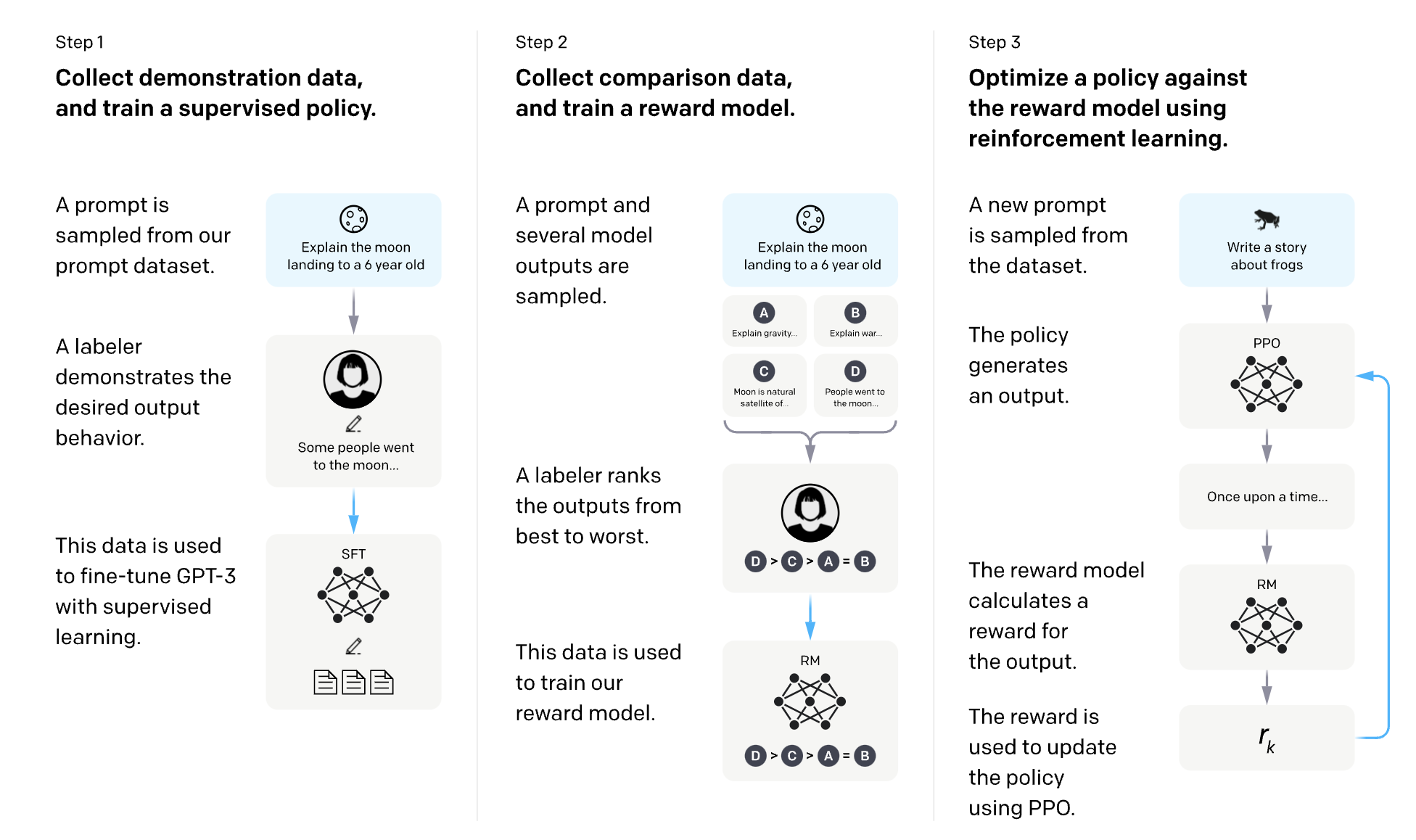
LimitationsWhile RLHF has been shown to improve the overall performance of language models, it is not without its limitations.One major issue is hallucination, where the model generates convincing, but false or misleading information. Some researchers believe that hallucination occurs because the model lacks an understanding of the cause and effect of its actions, while others attribute it to the mismatch between the model's internal knowledge and the human labelers' knowledge. Efforts are being made to address this issue, such as asking the model to explain the sources of its answers or punishing it more severely for making things up.DPOAnother approach to improving language models is Direct Policy Optimization (DPO), which aims to directly optimize the model's output to align with human preferences. Unlike RLHF, which relies on a separate reward model to guide the optimization process, DPO directly uses human feedback to update the language model's parameters.Imagine you're teaching a student to write an essay. With RLHF, you'd have a separate "grading model" that scores the student's essays, and the student would try to optimize their writing to get a better grade from this model. In contrast, with DPO, you'd directly provide feedback on the student's writing, and they would update their writing style based on your suggestions. According to the , this direct approach can lead to more efficient and effective optimization, as the model learns directly from human preferences rather than relying on a potentially imperfect reward model. However, DPO may require more human feedback and computational resources compared to RLHF, as the model needs to be updated with each round of feedback.Further improvementsTechniques such as few-shot prompting, chain of thought reasoning, and Retrieval Augmented Generation (RAG) all improve the accuracy of these models and mitigate hallucinations. In a future article, I’ll go into further detail about what these techniques include, their strengths and weaknesses, and how you can implement them in real-world applications.To summarize…Language models offer immense flexibility. You can think of these language models as college students who can be instructed to complete a large variety of tasks. In contrast, traditional ML models are like genetically editing and growing a new person in a test tube each time you want a new task completed.With a better understanding of how these LLMs are trained, you can hopefully find ways to improve your LLM for your application.
Please reach out to me at vedantk@stanford.edu, I love talking about this.